チャットGPTとの連携で医師の診断精度は向上する?
以下は、記事の抜粋です。
チャットGPTの確率に基づく推論を考慮することが診断に大いに役立つ可能性のあることが、新たな研究で示唆された。
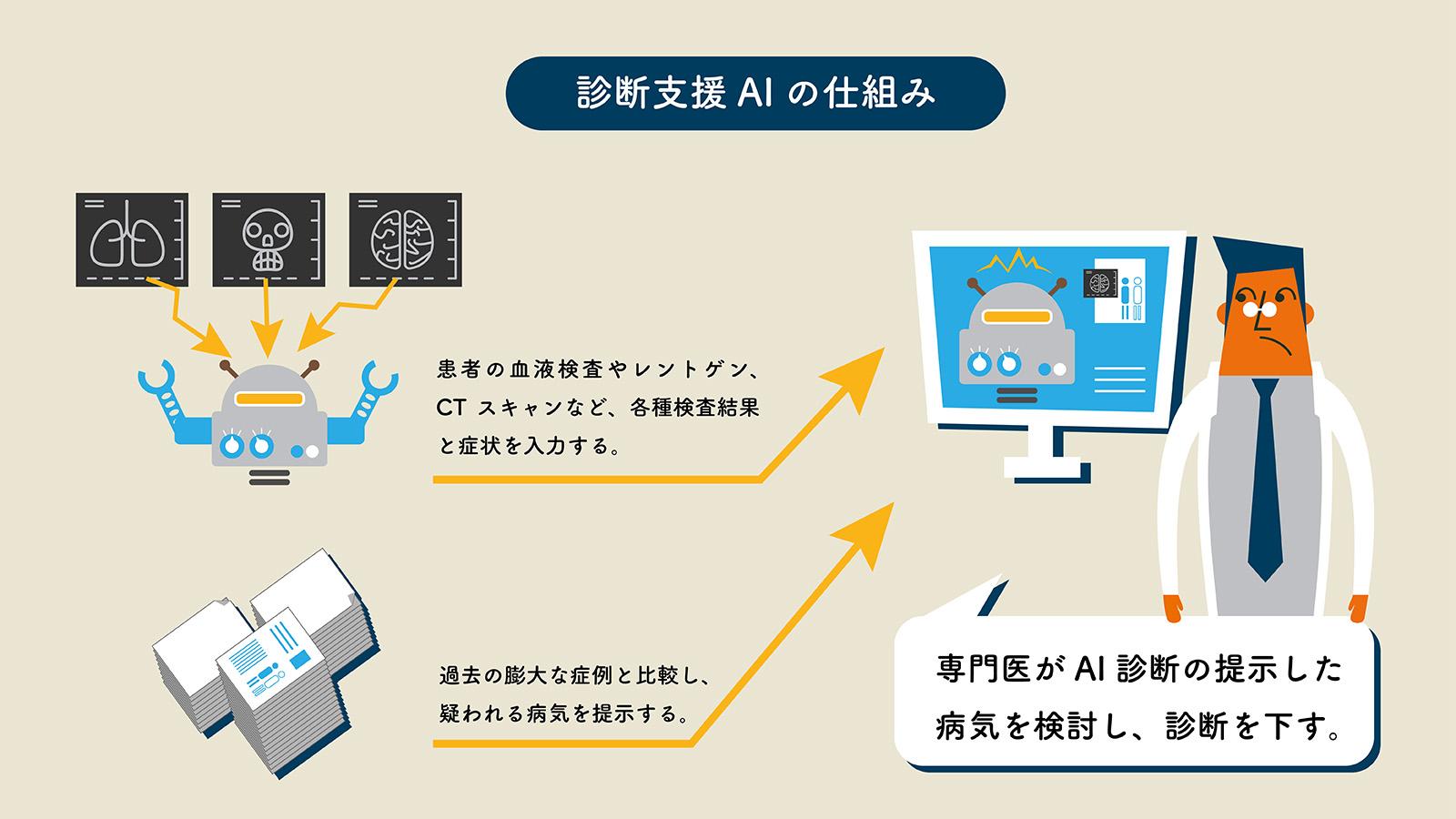
ベス・イスラエル・ディーコネス医療センターのRodman氏らの研究では、過去の調査データを用いて、医師による確率的推論とOpenAI社が開発した大規模言語モデル(LLM)であるGPT-4による確率的推論の比較が行われた。
調査データは、2018年6月1日から2019年11月26日の間に収集されたもので、553人の医師が5つの症例について確率的推論を行い、診断を下していた。症例には、肺炎の胸部X線画像、乳がんのマンモグラフィの画像、冠動脈疾患のストレステスト、尿路感染症の尿培養などの医療検査の情報が含まれていた。Rodman氏らは同じ情報をGPT-4にも与え、温度(AIが生成する内容のランダム性や創造性を調整するパラメーターで、高いほど出力内容が多様になる)1.0の設定で症例ごとにLLMを100回実行。その結果から推定値の中央値を算出し、人間のパフォーマンスと比較した。
その結果、GPT-4は5つの症例全てで、検査結果が陰性だった場合の検査前確率と検査後確率において、人間よりも誤差が小さいことが明らかになった。例えば、無症候性の細菌感染症例の場合、検査前確率はGPT-4で26%、人間で20%、平均絶対誤差(平均絶対パーセンテージ誤差)はそれぞれ、26.2(5240%)と32.2(6450%)であり、GPT-4の方が人間よりも予測精度が高かった。
Rodman氏はこの結果を受け、「人間は、検査での陰性判定後にリスクを実際よりも高く見積もることがあり、それが過剰治療や検査数の増加、薬剤の過剰投与につながることがある」と説明している。
また、全体的に見て、GPT-4は人間よりも、特に検査で陰性が判明した症例において予測のばらつきが少なく、より一貫性のある予測を行っていることがうかがわれた。さらに、GPT-4の検査での陽性判明後の検査後確率は、2症例では人間よりも正確であり、別の2症例での正確度は同等であり、1症例では人間の方が正確だった。
研究グループは、将来的には医師がAIと連携して、患者の診断をより正確に行えるようになる可能性があるとの見方を示す。
元論文のタイトルは、”Artificial Intelligence vs Clinician Performance in Estimating Probabilities of Diagnoses Before and After Testing(検査前後の診断確率推定における人工知能と臨床医のパフォーマンス比較)”です(論文をみる)。
個人情報の保護に課題はありそうですが、電子カルテの診療補助機能として、チャットGPTなどのAIが必須の機能になると思います。私を含めてAI依存症の医者がたくさんできそうです。


コメント