
OpenAIが「GPT-4o」を発表、人間と同等の速さでテキスト・音声・カメラ入力を処理可能で「周囲を見渡して状況判断」「数学の解き方を教える」「AI同士で会話して作曲」など多様な操作を実行可能
以下は、記事の抜粋です。
OpenAIが日本時間の2024年5月14日にAIモデル「GPT-4o」を発表しました。
Hello GPT-4o | OpenAI
https://openai.com/index/hello-gpt-4o/
Introducing GPT-4o and more tools to ChatGPT free users | OpenAI
https://openai.com/index/gpt-4o-and-more-tools-to-chatgpt-free/
GPT-4oはテキスト、音声、視覚入力を高速処理できるマルチモーダルなAIモデルです。GPT-4oの応答時間は平均320ミリ秒で、音声入力にはわずか232ミリ秒という人間と同等の速度で応答可能です。
GPT-4やGPT-3.5を搭載したChatGPTの音声会話モードは「音声をテキストに変換するモデル」「入力テキストを元に返答テキストを生成するモデル」「返答テキストを音声に変換するモデル」といった複数のモデルを用いて実現されていました。これに対して、GPT-4oは単一のモデルで「音声や画像、映像などの入力を受け取ってから返答する」という処理を実行可能です。
GPT-4oの発表に際して、多数のリアルタイム応答デモが実施されました。例えば、以下のデモではスマートフォンで周囲を撮影しつつ「私がここで何をするつもりか推測してみてください」という質問に対して返答しています。
チャットAIが苦手とする数学に関するデモもあります。以下のデモでは、「息子に答えは教えず問題の解き方を教えてあげて」という指示に対して、GPT-4oは問題が三角関数に関するものだと認識したうえで問題の解き方を一歩ずつ教えることができています。
以下の動画では、「カメラ入力を有効化したGPT-4o」と「カメラ入力を無効化したGPT-4o」を用意し、互いを会話させながら周囲の状況を把握させています。さらに、動画の4分27秒頃からは「今起こったことについて歌を歌って」という指示に従ってGPT-4oが歌う様子を確認できます。
さらに、GPT-4oは「画像を指示に従って加工する」という処理も可能です。以下の例では、GPT-4oが入力された顔写真をイラストに変換しています。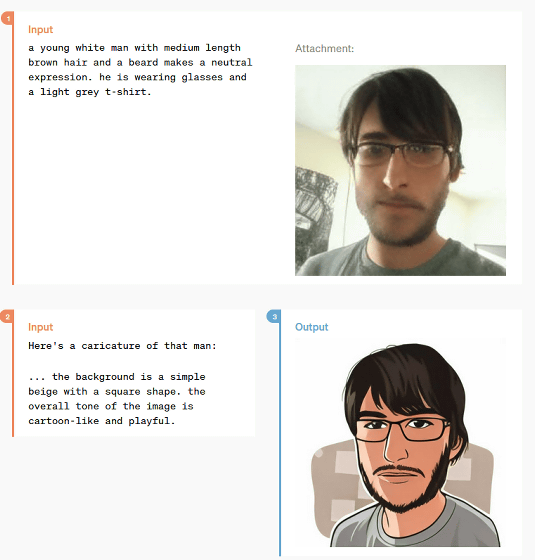
GPT-4oはすでにChatGPT Plusの加入者向けに公開されており、テキスト会話や音声会話などの機能を利用可能です。また、無料ユーザーに対してもテキストおよび視覚処理機能が2024年5月14日から順次展開されており、数週間以内にGPT-4oを使った音声モードも提供される予定です。
AIは、すごいスピードで進化しています。自分も含めてヒトの仕事がどれほど奪われるのかは気になりますが、X線写真や心電図、超音波診断などへの実用化が待ち遠しいです。


コメント